C++ 拾遗
本文主要用于总结一些比较少用但又比较有意思的 C++ 特性
变量&类型
内存
IEEE 754
浮点数精度有限,了解浮点数实现方法可以减少精度相关的错误,参考 wiki 上对单精度浮点数 float 的解释,浮点数由三部分组成:符号位、指数位和小数位,float 分别对应 1 位、8 位和 23 位。已知 32bit float 内存分布,其代表的浮点数(Value)计算方式如下:
\[\text { value }=(-1)^{\text {sign }} \times 2^{(E-127)} \times\left(1+\sum_{i=1}^{23} b_{23-i} 2^{-i}\right) \]
小数位的变化是线性的,而指数位的变化是指数级(\(2^{(E-127)}\)),故浮点数表示的离散数值在坐标轴上是不均匀的,离原点越近,浮点数精度越高,因为离散数值分布密度越高(\(2^{(E-127)}\) 作为间隔,离 0 越近,越小)。以 8bit 浮点数 为例,其数值在坐标上的分布如下图

十进制数和浮点数内存表示的转换可以参考这里。浮点数取值范围如下(参考):
\[\begin{array}{|c|c|c|c|} \hline \text { Level } & \text { Width } & \text { Range at full precision } & \text { Precision }{ } \\ \hline \text { float } & 32 \text { bits } & \pm 1.18 \times 10^{-38} \text { to } \pm 3.4 \times 10^{38} & \text { Appr } 7 \text { decimal digits } \\ \hline \text { double } & 64 \text { bits } & \pm 2.23 \times 10^{-308} \text { to } \pm 1.80 \times 10^{308} & \text { Appr 16 decimal digits } \\ \hline \end{array} \]
单精度浮点数小数位有 23bits(\(2^{23}=8388608\),7 位十进制数),双精度有 52bits(\(2^{52}=4503599627370496\),16 位十进制数)。由此可见,浮点数的分辨率跟小数位位长度息息相关。单双精度浮点数指数位长度分别为 8bits 和 11bits,因为指数要同时表示大于和小于 0 的数值,故其最大值大概是 \(2^{2^7}=2^{128}=10^{38.5318...}\) 和 \(2^{2^{10}}=2^{1024}=10^{308.2547...}\)
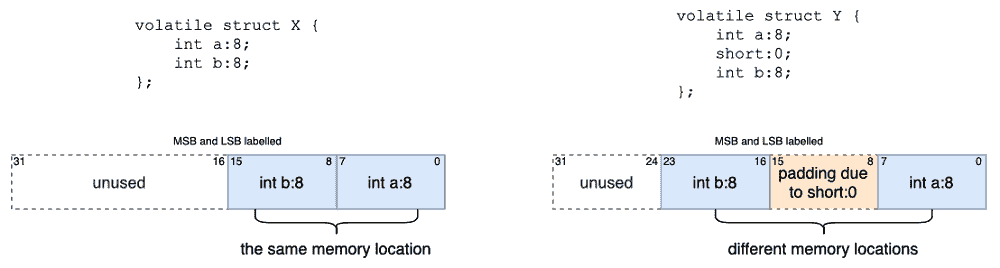
位域
位域(Bit-field)可以实现更紧凑的变量内存分布。在损失一些安全性的前提下,获得更紧凑的内存布局
非受限联合类型
C++11 后联合类型(union)的成员可以是除了引用类型外的所有类型。如果有联合类型中存在非平凡类型,那么这个联合类型的特殊成员函数将被隐式删除,所以我们必须手动调用联合体(或对应成员)的析构函数
FAMs
柔性数组(Flexible Array Members,FAM)是 C99 引入的语言特性,在一些场景下可以提升内存使用效率。C++ 标准当前还不支持,但已经有提案且常见编译器也支持这类操作。需要注意,使用 sizeof 计算结构体时,最后那个“柔性”变量所占用的内存空间为 0
内存对齐
不同编译器对 #pragma pack(x) 和 alignas 的优先级定义不同,同时使用两者的风险是相同的代码在不同的平台下有着不同的行为
内存对齐的目的在于提升系统访问内存的效率,系统从内存中读取数据一般是以块为主,且块的首地址一般是 \(2^n\) 的整数倍。C++17 前通过 new/malloc 创建的内存都是已经对齐的,故首地址一定是 std::alignof(std::max_align_t) 的整数倍
C++17 后,可以为 new 提供两个参数,其中第二个参数用于设置内存地址对齐字节数,且 C++17 后 new 会根据类型对齐要求分配内存,而 C++11 则只会依据 std::max_align_t 的对齐要求来分配内存。alignof(std::max_align_t) 一般是 8 或者 16,所以所有的标量类型都适应 std::max_align_t 的对齐字节长度
C++11 提供了两个内存对齐关键字:alignof 和 alignas,工具:std::aligned_storage、std::aligned_union、std::align,返回指定缓冲区中最近的能找到符合指定对齐字节长度的指针。拷贝满足对齐要求的内存比未对齐的内存要快
结构体中对齐规则很多时候都是为了读取效率,例如结构体至少与内部最大成员变量对齐保持一致,如此读取相关成员时会更高效
茴香豆 new
new 有 new operator、operator new 和 placement new 三种类型,new 重载也有不同形式,可以在使用的时候查询相关资料
ABI 兼容
ABI(Application Binary Interface)应用程序二进制接口,描述了应用程序和操作系统之间,一个应用和它的库之间,或者应用的组成部分之间的低接口。如果没有一个稳定的 ABI,就必须使用同一编译器的同一版本编译程序的所有部分。ABI 兼容是 C/C++ 系统,特别是大型系统的重要内容
ABI 兼容问题本文不做介绍,为满足 C/C++ 系统的 ABI 兼容,需要满足一定的编码规范,细节可以参考:[Policies/Binary Compatibility Issues With C++[^9]
字面值(literal)
除编译器内置字面值工具外,我们可以自定义字面值函数,用户可以很方便的在表达式中将整数、字符和字符串字面值转换为对象
变量
使用编译器内置的字面值工具,我们可以在表达式中直接指定变量的类型,细节请参考 Integer literal 或者 Floating-point literal
unsigned long long l1 = 18446744073709550592ull; // C++11
unsigned long long l2 = 18'446'744'073'709'550'592llu; // C++14
3.4028234e38f // float
3.4028234e38l // long double
字符&字符集
字符字面值可以指明字符/字符串的编码方式。C++ 支持变长编码 u8 和定长字符编码 u、U。真实的 utf16 是变长编码,但因为需要更多字节表示的字符比较少,所以 C++ 中使用固定长度的变量来实现 utf16。编译器一般拒绝编译目标变量无法表示的字符并提示:character constant too long for its type
u8 在 C++11 中不支持字符编码(支持字符串),C++17 之后才支持,C++20 引入了 char8_t 类型,u8 对应的返回类型只能是 char8_t,所以下面代码用 C++20 标准进行编译将失败 。utf 编码知识可以参考这里
char u8[] = u8'猫'; // C++ 17 编译通过,C++ 20 将失败
char u8_str[] = u8"猫"; // C++ 11
// C++11 之前的 `wchar_t` 关键字因为没有指定位宽,所以无法实现跨平台操作
char16_t u16 = u'猫';
char32_t U32 = U'猫';
中日韩统一表意文字(CJK Unified Ideographs)区存储了一些常用的汉字,一些特殊的汉字存储在了扩展区,细节可以参考 Unicode 官网文档。CKJ 基本区域也在随着时间的变化而变化,Unicode 1.0.1 中这个区域是 u4e00-u9fa5,Unicode 15 中这个区域是 : 4E00–9FFF。CKJ 扩展区的一些汉字也可以使用两字节进行编码,细节可参考 East Asian Scripts
东亚文字的特殊性给编码与使用造成了一定的困难,例如中文正则匹配,不过当前一些正则表达式库已经支持使用关键字匹配汉字,具体细节可以参考:JavaScript 正则表达式匹配汉字
编码效率
内联/嵌套 命名空间
内联命名空间(C++11)能够把空间内函数和类型导出到父命名空间中,这样即使不指定子命名空间也可以使用其空间 内的函数和类型。该特性可以帮助库作者无缝升级库代码,让客户不用修改任何代码也能够自由选择新老库代码。嵌套命名空间可以简化命名空间的语法,具体细节可参考官网
委托构造函数
为了合理复用构造函数来减少代码冗余,C++11标准支持了委托构造函数:某个类型的一个构造函数可以委托同类型的另一个构造函数对对象进行初始化
初始化列表
有初始化列表的代码,编译器负责将列表里的元素(大括号包含的内容)构造为一个 std::initializer_list 的对象,然后寻找支持 std:: initializer_list 为形参的函数并调用它
如果有一个类同时拥有满足列表初始化的构造函数,且其中一个是以 std::initializer_list 为参数,那么编译器将优先以 std::initializer_ list 为参数构造函数,如果没有 init_list 形参的构造,则退化并尝试调用其他形式的构造函数
模板
模板别名
模板别名(alias template)可以减少模板类型的长度,比 typedef 更方便,例如可省略模板有待决断类型时的 typename 关键字
template<class T>
using int_map = std::map<int, T>;
SFINAE
SFINAE(Substitution Failure Is Not An Error,替换失败不是错误)主要是指在函数模板重载时,当模板形参替换为指定的实参或由函数实参推导出模板形参的过程中出现了失败,则放弃这个重载而不是抛出一个编译失败
编译时工具
静态断言
static_assert,C++17 之前必须提供两个参数,之后只提供一个即可
兼容性问题
聚合类型
这里要先明确 C++ 中对 Aggregates 的定义,细节请参考:is_aggregate<...>
C++11/17/20 对聚合类型做了一定的修改与扩展,从而引入了一些兼容性问题。C++17 后非私有继承的类型也有可能成为聚合类型,聚合类型的初始化方法和传统类有一定的区别,所以会造成 C++11/14 和 C++17 的不兼容。C++20 后聚合类可以使用圆括号初始化,C++20 之前是不允许的。细节请参考 《现代C++语言核心特性解析》 第十五章
C++20 后,对于聚合类型,可以使用类似于 Python 的指定初始化
struct Point3D { int x; int y; int z; };
Point3D p{ .z = 3 };
其他
decltype
decltype 可以解决右值引用传播截断的问题。注意使用 decltype 时包含变量的括号,包含括号将产生引用类型
decltype(auto) 的作用简单来说,就是告诉编译器用 decltype 的推导表达式规则来推导 auto。另外需要注意的是,decltype(auto) 必须单独声明,也就是它不能结合指针、引用以及 cv 限定符
decltype(auto) *x5d = &i; // 编译失败,decltype(auto)必须单独声明
求值顺序
C++/C 没有对求值顺序做严格的规范,例如 std::cout << f() << g() << h(); 的行为在不同编译环境下可能不同,因为 f/g/h 这三个函数执行时间没有严格的约束
C++17 之后标准对求值顺序做了一些要求(Order of evaluation),例如 从C++17 开始,函数表达式一定会在函数的参数之前求值,不过参数求值顺序依旧没有约束。为了避免求值顺序造成一些问题,可以拆分表达式
nullptr_t
nullptr 的数据类型是 nullptr_t,nullptr 是关键字,且其数据是纯右值