并发编程-基础
向量化与多核心技术是未来高性能计算的一个趋势。并发算法的优劣有多个评价标准,例如:正确性、可扩展性(随着硬件核心数的增加,算法性能也会随之增加)、可维护性等。并发编程相比于传统的串行编程有一定的难度,例如:任务/资源划分、并发访问控制等
除了并行,还有其他方法可以提升系统性能,例如运行多个程序实例、使用已有的库(例如 MKL、TBB、CUDA 等)、优化串行程序等
现代处理器
并行技术
- 矢量化,SIMT、SIMD。例如 x86 提供的 AVX/SSE 指令
- 指令级并行,流水线、多发射、VLIW、乱序执行、分支预测等
- 实际 CPU 核心可以同时对多条指令求值,这称为指令级并行(多发射)。指令级并行要求同时执行的指令之间没有数据或控制依赖,因为多发射指令依旧使用同一套硬件资源
- 每时钟周期超过一条指令的吞吐量,称之为超标量。x86 Haswell 一个时钟周期的吞吐量是 4 次整形加法、两次单精度浮点乘法;因为流水线的存在,一个乘法指令需要三个周期,一次除法是十几个周期。精简指令集(RISC)CPU 的指令一般只操作寄存器,内存的操作有专用的命令 load/store;复杂指令集(RISC)CPU 的指令同时包含了内存 load、寄存器操作和内存 store,这是指令流水线的基本思想
- 因为 CPU 多发射与流水线,如果前后指令没有关联,后续指令可能会被优先发射(issue),这是 CPU 乱序执行的基本思想。例如后续指令的 load 子命令可能会被尽早触发。乱序执行的硬件基础是 Register Renaming,CPU 内部寄存器个数远大于通用寄存器的个数,而这些寄存器都可以作为通用寄存器使用,CPU 将自行决定通用寄存器与硬件寄存器之间的映射关系
- 线程级并行,多核心&超线程(SMP、NUMA、GPU和集群等方式)
- 超线程,超线程通过双倍增加一些资源(PC 和寄存器,实现在单个时钟周期内在两个线程间切换) 来减少线程的切换代价,但是因为只有一份执行单元,因此其峰值计算能力并没有提高。对于指令类型丰富且多的应用,超线程能够很好地提升性能。在某些应用上性能可能会下降,而在绝大多数应用上提升不会超过 20%
- 常用的多线程库有:pthread、win32 thread、OpenMP、C++ std thread、OpenCL、CUDA、OpenACC 等
- 缓存层次结构,缓存及 NUMA(One can view NUMA as a tightly coupled form of cluster computing)
- x86 Haswell 核心,一次内存访问需要 200 周期左右
- 处理器吞吐量与内存吞吐量和延迟的差异越来越大,这称为内存墙
- 处理器具有多级缓存,缓存数据一致性由一致性协议保证(例如 MESI)。因为大部分现代编译器使用弱一致性协议,而且缓存一致性不保证顺序一致性,所以多个控制流(线程)读写一个变量还是有问题
虚拟存储 & TLB
虚拟存储器是对内存和 io 设备(包括硬盘)的抽象,通过将内存中的数据切换到硬盘,它使得进程好像拥有了比整个内存容量大得多的内存空间。由于从虚拟地址到物理地址的转换非常耗时,处理器和操作系统主要使用了两个优化来减少转换次数:分页机制、TLB(TLB 用于缓存已经翻译的虚拟地址,通过利用访问页的局部性来减少翻译次数)
SIMD
SIMD 的全称是 Single Instruction Multiple Data,中文名“单指令多数据”,即一条指令处理多个数据
SSE/AVX
SSE/AVX 指令支持向量化数据并行,一个指令可以同时对多个数据进行操作,同时操作的数据个数由向量寄存器的长度和数据类型共同决定。SSE 几乎支持所有常用的算术运算,故大多数算法只要满足向量化数据并行的特点, 就有可能能够使用指令进行向量化
SSE/AVX 指令集对分支的处理能力非常差,而从向量中抽取某些元素数据的代价又非常大,因此不适合含有复杂逻辑的运算
NEON
NEON 是 ARM Cortex A 系列处理器支持的数据并行技术,和 SSE/AVX 类似:一条指令以指令级 SIMD 的方式同时对多个数据进行操作,同时,操作的数据个数由向量寄存器的长度和数据类型共同决定
存储模型
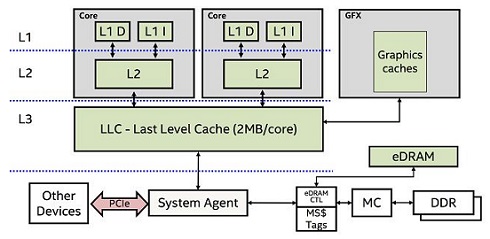
参考相关资料,在 CPU 芯片制程大部分小于等于 7nm 的今天(2022),CPU 中一级缓存和内存访问延迟依旧有近百倍的差距,这也是大部分 CPU 在不断增加缓存大小的原因:尽量减少对内存的访问
CPU 内部缓存行(Cache line)与内存的交换一般以块为单位(比如 64Bytes),所以一些操作需要内存对齐这类操作,因为对齐的内存数据可以减少内存和缓存之间交换的次数,从而提升性能。当然还可以从其他角度理解内存对齐,比如内存的存取方式等
如上图所示,现代 CPU 有多个核心(Cores),每个核心有自己的二级和一级缓存(L2、L1),三级缓存(L3)一般是片上多个核心共享的。不同核心之间 L1/L2 缓存的同步会消耗资源与时间,所以多线程场景下为了提升性能(例如避免打断流水线和多发射),编译器和 CPU 都会减少不同 Core 中 L1/L2 缓存的同步(不同 Core 读写内存中同一位置,为保持数据的一致性,一个 Core 的修改可能触发另一个 Core 缓存的更新,这个过程可以看作是不同核心缓存行的同步)。为了达到这个目的,多线程场景下如果没有同步限制(例如锁、原子变量或者内存屏障等机制),多个线程同时读写同一个共享变量时,执行不同线程的 Core,其 L1/L2 缓存行中会有这个共享变量不同的副本。缓存行会不定时与内存进行同步,不一致的缓存会造成内存中对应数据的混乱,从而造成不可预知的值与结果
并发编程模式
Map&Reduce
map,对每个数据施加同样的运算,map 模式操作的数据表现出了数据并行的特征;reduce,从多个输人中产生一个输出,在不考虑误差的前提下,输出与输入的多个数据的顺序无关
// map
void cal_squar(vec& in, vec& out) {
for (i...) {
out[i] = map_func(in[i]);
}
}
// reduce
float sum(vec& in) {
float res = 0;
for(e:in) res += e;
return res;
}
Scan
scan 模式常被成为“前缀和”
void scan(vec &data) {
float tmp = data[0];
for(auto &e:data){
tmp += e;
e = tmp;
}
}
Zip/Unzip
对于串行程序而言,由结构体组成的数组(简称 AOS)对缓存的利用更好,表达数据也更为直观。而数组组成的结构体(简称 SOA)则更易于并行化和使用处理器支持的 SIMD 指令。 zip 模式用来将数组组成的结构体转换成结构体组成的数组, 而 unzip 模式刚好相反
流水线模式
流水线模式与指令流水线类似,通过并行使用不同硬件资源的操作来获得髙性能
C++ 并行工具
thread 库是 C++ 11 之后引入的标准库多线程工具,标准库之外还有其他通用的并行编程工具
Libs
TBB
TBB 是 Intel 出品的 C++ 多线程模板库,提供了大量高性能并行接口,细节可参考 github 或者《Pro TBB》
SIMD libs
github 上有不少非常优秀的 SIMD 相关 lib,例如 highway、libsimdpp 等
Network&RPC
OpenMP
OpenMP(Open Multi-Processing, 开放多处理)是一种支持多平台共享存储器多处理器编程的 C/C++ 和 Fortran 语言的规范和 API。OpenMP 支持许多体系结构的处理器和操作系统,OpenMP 独立于处理器架构和操作系统,使用 GCC 编译 OpenMP 程序时,只需要在编译命令中加上 -fopenmp 选项即可
OpenMP 支持数据并行,也支持任务并行,它的并行模型采用传统的 fork-join。由一个主线程建立(fork)许多子线程,在一定的时候主线程再收回(join)所有子线程
比较新的 OpenMP 标准支持嵌套(nest)线程,为了编写可移植的代码,不建议使用嵌套的 parallel 伪指令
并行级别:OpenMP 支持异构计算(OpenMP 4.0 加入)、任务(task)、线程(例如 parallel for)和指令级别(例如 SIMD)
同步方式:锁(mutex)、原子操作(atomic)
GPU: CUDA&OpenCL
异构并行计算是指平台上的多个计算部件协同, 以最大程度发挥平台整体的计算能力。通常异构平台包含的计算部件如和其他一些加速部件
OpenACC
OpenACC 是 NVIDIA 联合 PGI ( The Portland Group)、 Cray、 Caps (已经倒闭) 建立的一个用于加速器加速、 类似 OpenMP 的编译制导语句标准