相关性搜索简介——常规技术与应用
参考资料:《信息检索导论》 // 《Lucene in action, 2ed》 & code // Lucene 8.11 Doc // 《Practical Apache Lucene 8》 // 《相关性搜索》 & code // 《精通特征工程》 //
《Lucene in action, 2ed》基于老版 Lucene 3.0(2021 年 Lucene 已经发展到 8.xx,历史版本可参考 Lucene Change log),但依旧可以使用这本书了解 Lucene 和信息检索的基本概念
本文是我对搜索技术与应用学习的总结,包括搜索的底层数据结构与基础算法。机器学习在搜索中的应用将在其他博文中介绍。阅读本文需要有一定的算法基础和搜索经验,最好使用过 ElasticSearch、Solr 或者 Lucene 等搜索相关工具
相关性搜索
相关性是一种改进用户搜索结果的实践,它在用户体验的具体上下文中满足用户的信息需求,同时平衡排名对业务需求的影响
随着时代的发展,我们被海量的信息所包围,快速有效的获取信息是非常重要的研究课题。现阶段,相关性搜索是我们获取信息的重要技术手段。信息检索(Information Retrieval, IR)是相关性搜索的技术基础
相关性搜索有其自身的复杂性,因为不同场景下的相关性有不同的意义,而且搜索引擎除了满足用户相关性需求外也要满足业务需求,所以搜索业务需要技术人员和业务人员一起努力实现
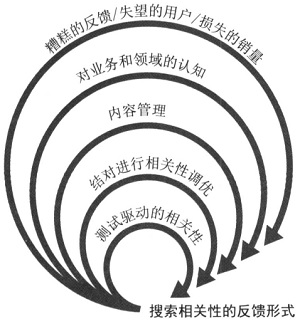
下面是不同场景下对搜索的要求
- Web 搜索中为了剔除虚假网站,Google 开发出了 PageRank 等算法,用网页之间的相关性剔除恶意网页
- Amazon 等电商网站没有虚假网站的问题,但为了盈利,搜索引擎需要考虑其他方面的因素,例如清理库存等。从用户的角度来说,除了相关性,物美价廉是电商搜索的默认因素
- 租房搜索网站还需要考虑距离、学校、房间数等因素
- 对于百科、空间、博客相关网站的搜索工具,过滤过激、暴力和违法等信息也是非常重要的功能
- 专家搜索。在法律、医疗和研究等领域,专业词语之间的转换需要专业的知识
- 其他领域。图片、歌曲、视频的相关性搜索也有各自的技术特点。结合深度学习实现多媒体的搜索也是相关性检索的重要应用场景
构造相关性搜索工具
graph LR
A[搜集信息和需求]
B[设计搜索应用]
C[部署监控与改进]
A-->B
B-->C
- 搜集信息和需求
- 理解用户及信息需求;搜集必要的搜索信息,例如文档、位置、价格等等
- 领域专家与专业用户的建议非常重要。反馈与内容管理是搜索引擎进行改进的核心驱动
- 明确业务需求,免费还是付费等
- 理解用户及信息需求;搜集必要的搜索信息,例如文档、位置、价格等等
- 设计搜索应用
- 实用搜索引擎有多种改善搜索体验的工具,例如返回搜索文档时返回部分高亮文档,用于告知用户为什么文档会命中;搜索界面 UI 简单易用,提供一些额外的功能,比如拼写纠正、搜索提示等
- 部署监控与改进
- 保留用户搜索行为日志,便于后续分析改进搜索策略。行为日志包括但不限于用户搜索词、搜索结果、页面停留时间、转化率、用户黏度和翻页信息等
- 监控数据可以用户机器学习的素材,使用统计方式提升搜索体验
- 其他
- 保留用户搜索行为日志,便于后续分析改进搜索策略。行为日志包括但不限于用户搜索词、搜索结果、页面停留时间、转化率、用户黏度和翻页信息等
检索的技术基础
graph TB
A[search tech]
B[正/倒排索引]
C[搜索模型]
D[bool/向量/概率]
E[特征提取]
F[分词]
G[语义提取]
H[TFIDF]
I[非文本]
J[音频<br/>Parsons code]
K[视频语义]
L[特征扩展]
M[同义词<br/>word2vec]
O[文本特征]
P[地理位置]
A-->B
A-->C
C-->D
A-->E
E-->O
O-->F
O-->G
O-->H
E-->I
I-->J
I-->K
E-->L
L-->M
I-->P
倒(正)排索引
相关知识请参考其他书籍或 ES 官方简介。正排索引常用于聚类分析,倒排索引则用于检索
倒排索引中的 token 还有很多其他属性,比如:文档频率、词频、词位置、词偏移量、负载数据、存储字段、文档值等,这些属性可以用于相关性分析
搜索只能搜索到被索引的词项(Term),所以文档的检索过程会深刻影响搜索结果。比如过滤了 stopword 的搜索引擎如果不做其他处理即使添加相关文章也搜索不到 to be or not to be ,此时应该添加短语提取模型
相关性排序
检索到的文档展现给用户时是有顺序的,排序使用的是相关性。ElasticSearch (ES) 中的 relevancy explains,是对检索结果得分的详细说明,是底层打分细节,在分析检索结果时非常有用
搜索理论模型
- 布尔查询,没有匹配得分。文档要么匹配要么不匹配查询语句。细节可以参考 Lucene 布尔查询。Lucene 的布尔查询提供了 must(+)、should 和
must_not(-)三种形式,例如black -cat +dog - 向量模型,查询语句和文档都被转换为高维向量,查询结果是两个向量的距离,比如余弦距离。向量模型常用于查找相似项,因为推荐和搜索息息相关,所以向量模型在推荐系统中也比较常见
- 概率模型,计算查询语句和文档的相似度,使用概率度量(常基于贝叶斯)。典型的概率模型是 BM25
文本特征化

特征是原始数据的数值表示。在机器学习流程中,特征是数据和模型之间的纽带,正确的特征可以减轻构建模型的难度,从而使机器学习流程输出更高质量的结果
上面对特征和机器学习之间关系的描述也适用于相关性搜索,文本特征化是一切搜索的前提。搜索研发很大一部分工作是在做特征提取,发现与构造特征。相关性搜索中常见的特征处理方法有词袋、N 元词袋等。基于朴素词袋的方法无法提取词语之间的语义,而且如果不做过滤,简单的词袋会充斥着大量的无效单词(比如 stopword)和海量没有实际意义的短语,造成存储与计算资源的浪费
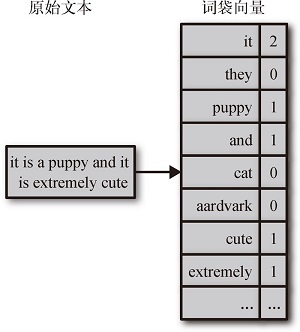
分词
分词是用来提取语义而非单词的
分词一般同时用在查询语句和待查资料。分词不是简单的提取单词,而是将真实语义转化为 token,比较常用的技术手段有标准化、差异化、词干分析和语音分析等。例如 apples 标准化为 apple,甚至直接转化为词干 appl。不少应用场景会同时使用多种形式的分析器处理同一个字段(ES 中支持同一个字段使用多个分析器:multi-filed mapping ),从而获得更为丰富的语义 token
- 分隔符处理。例如:缩略词:I.B.M -> IBM、N.E.W->new enginerring week;不同类型的电话号码分词
- 获得同义词的语义 & 为专指性建模。例如 dog 可以转化为 beagle、poodle
- 分词应用场景的多样性:数值、日期、地理位置、图像、形状、质地和声音等等
- 简单的音频分词可以直接将音频转换为U、D 和 R三种类型的文本序列(Parsons code),U/D/R分别表示当前音相比于前置音高/低/不变。结合 N 元词袋等方法可实现搜索
短语和词位置 & PhraseQuery & shingle
单词的相对位置有时是重要的信息。有些短语不能随意把单词拆开作为独立的单词进行使用,比如礼服鞋 dress shoes ,如果将短语拆开查询,返回的页面可能包含女士服装,这个一般不是用户需要的。Lucene 提供了 PhraseQuery 接口用于查询单词间有位置关系的短语
ES 提供了 shingle 过滤器,可以个性化生成 n-grams 短语 token
有效的语义 token
为提升词袋法的有效性,可以使用不同的方法处理原始数据,比如 TF·IDF、词干提取、word2vec、短语搭配提取(Collocations)等,NLP 中使用的技术常用于搜索。这里需要注意,不相邻的单词也有可能组成有效的短语
以统计方法(包括机器学习)为例,用于训练短语提取模型的语料库越丰富,模型的短语提取能力越强。当然,由专业领域语料库训练出的模型在其他场景的表现就不一定好。随着时代的发展,常用短语也在不断的变化,算法与语料库的持续更新也是必需的
为提取有效的语义 token,使用不同算法与工具处理相同文本是常用的手段
TF·IDF
不同属性不同位置的 token 其重要性一般不同,TF·IDF 是用于描述 token 显著性的一种手段
- TF 是单词在文档中出现的频率,出现的越多说明越重要。但对 the、a 等 stopword 无效,所以需要 IDF 降权
- IDF 是逆文档频率,在大部分文档中都出现的单词,其重要性有所降低。IDF 用于描述单词的罕见程度
朴素的 TFIDF 也有一定的缺点,比如出现在文章标题处的单词和出现在引文中的单词,其权值不应该相同,所以各搜索引擎对 TFIDF 做了一定的修正,比如 Lucene 中所使用的 Okapi BM25
- 真实的 TF 对评分的影响一般不是线性的,常常被抑制,比如使用 \(sqrt(TF)\)
- 文章的长度也应该考虑在内,长文档出现更多单词的概率也更大
- 相同的单词出现在文章不同位置分数不同
使用搜索引擎时因为查询语句较短,所以查询语句一般不使用 TF 来评价单词的重要性。搜索引擎一般会提供方式来提升(boost)某些单词的显著性
调试搜索结果
graph TB
A[概念]
B[查全/查准率]
C[tools]
D[ES/Solr]
E[dsl->query str<br/>explain]
G[signal]
H[boost<br/>shingle]
I[best/most<br/>field]
J[词/字段为中心]
K[白化象<br/>认知偏差]
L[cross field<br/>字段同步]
M[dis max]
N[聚合字段<br/>copy to]
O[字段合并<br/>ES Nested field]
P[组合查询]
Q[boost分层]
R[bool<br/>fun score]
S[相关性反馈<br/>高亮/纠错/建议]
T[个性化搜索与推荐]
A-->B
A-->J
A-->G
J-->K
K-->L
K-->M
G-->P
J-->I
C-->D
D-->E
G-->H
K-->N
P-->Q
P-->R
B-->S
P-->O
下面的示例源自《相关性搜索》,细节请参考原书
查全率(Recall) & 查准率(Precision)
查全率和查准率有一定的相互作用,相同的算法一个指标的提升有可能会伴随着另一个指标的下降
- 查全率:查询结果集中返回的相关性文档占总相关文档的百分比
- 查准率:查询结果集中具有相关性的文档在结果集中的百分比
以水果为例,如果单以颜色(黄、绿、红)作为条件查询苹果,那么查全率几乎是 100%,但樱桃、橙子、梨、芒果和榴莲等水果也会混入到结果集中,查准率就比较低。查询时添加额外的条件可以改变查全率和查准率,比如大小、口感和种属等
使用朴素词袋算法进行文本查询可以获得较高的查准率,但查全率就会比较低,因为只有精确匹配的文档才会返回。所以常使用词干提取、小写转换、关键字文件等手段对查询语句和待查文本进行处理从而提高查全率。这从另一个角度说明分析不是简单的将单词转化为 token,而应该是将语义和用户意图转换为 token
ES DSL 与 Query String
ES 提供了一些接口,可以将 ES DSL 查询转换为底层 Lucene 使用的查询语句,示例如下:
GET /tmdb/movie/_validate/query?explain
{
"query": {
"multi_match": {
"query": "basketball with cartoon aliens",
"fields": ["title^10", "overview"] # 同时搜索标题和简介,并提升标题重要程度
}
}
}
下面是上面调用返回的 Lucene 查询语句,可以结合 Lucene 布尔查询 进行分析
+((overview:basketball overview:with overview:cartoon overview:aliens) |
(title:basketball title:with title:cartoon title:aliens)^10.0) #*:*"
从 Lucene 查询语句可知,单词 with 是一个非常重要的搜索因子,这是不合理的,从 ES 的返回结果也可以看出:
Num Relevance Score Movie Title
1 85.56929 Aliens
2 73.71077 The Basketball Diaries
...
9 45.221096 Friends with Benefits
通过分析,可以修改默认分词器,从而过滤 stopword。ES 不支持直接在已有索引上修改分析器,一般需要先创建一个新的索引,配置好 mapping 后再 _reindex,细节请参考这里
相关性计算细节
使用查询接口时如果置 explain 为 true,ES 将返回相关性计算细节,如下所示:
GET /tmdbenglish/_search
{
"explain": true,
"size": 100,
"_source": ["title"],
"query": { ... }
}
下面是打分过程的部分片段,从 explain 中可以看到 TF 和 IDF 等因素的计算细节
"_explanation" : {
"value" : 12.882349,
"description" : "max of:",
"details" : ...
}
信号建模
A signal is any component of the relevance-scoring calculation corresponding to meaningful, measurable user or business information
一些数据如果不做处理可能不利于搜索引擎索引。保存西方人名的关系型数据库常将 first/middle/last name 存储在不同的字段中,直接使用这类数据建立索引将割裂人名各部分的相关性,降低搜索精度
ES 与相关性建模
Elasticsearch has no concept of inner objects. Therefore, it flattens object hierarchies into a simple list of field names and values
相关性建模是搜索引擎和关系数据库一个非常重要的区别,后者常需要保证字段与字段、表与表之间数据的独立性,而前者需要建立相关性,将有一定关联的数据放在一起。例如搜索引擎常合并字段,在为原始数据创建索引时新增或者直接将原始数据的多个分立字段合并为一个新字段,形成一个新的可用信号
ElasticSearch(ES)默认会修改原始 JSON 文档中内嵌对象的存储格式,细节请参考 Nested field type。ES 默认会将 JSON 的数组类型扁平化从而加强部分字段的相关性(ES 提供配置方式修改默认数据存储格式),不过某些场景下会降低部分字段的相关性,具体使用需要看应用场景
boosting
多字段搜索时部分字段应该赋予更高的排序权重,ES 提供了 boosting 方式,方便用户指定字段的排序权重
shingle
shingle 是 ES 提供的 token filter,可以生成 n-grams 短语 token,方便实现个性化短语查询
ES 支持为同一个字段使用不同的分析器,所以同一个字段可以同时使用常规分析器和 n-gram 分析器。使用不同分析器的字段会生成不同名称的索引项,检索时指定索引项名称即可,细节请参考 ES:Multi-fields with multiple analyzers
Term/Field Centric
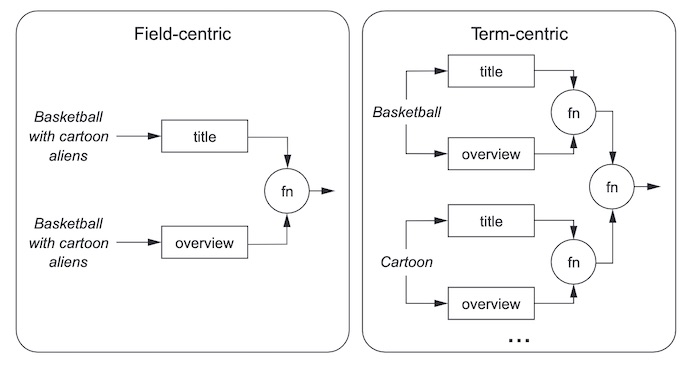
ES 支持词为中心(term-centric)和字段为中心(field-centric)的两种搜索排序方式,参考 ES 官网 或者这里。以词为中心的搜索更关注搜索词而不是内容
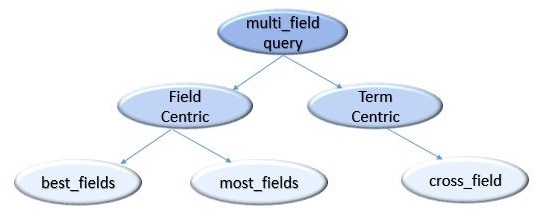
ES 中的 multi_match 方法默认使用 best_field 实现 field-centric 查询,另一种 field-centric 查询方法是 most_field;term-centric 常用查询方法是 cross_field。这三种查询方式的区别可以参考下面的 Lucene 语法。除上面介绍的三种查询方式, multi match 还支持 phrase/phrase_prefix/bool_prefix
# field-centric
(name:Best name:Laptop ) | (description:Best description:Laptop) # best_field, max(.)
(name:Best name:Laptop ) + (description:Best description:Laptop) # most_field, avg(.)
# term-centric
(name:Best description:Best) + (name:Laptop description:Laptop) # cross_field, avg(.)
不同搜索场景需要使用不同的相关性排序方式,搜索电影的时候用户可能只想搜索到明确的电影名、演员或者导演,这个时候用 best field 模型比较合适;论文或者网页搜索的时候用户更关心返回结果和搜索内容的相关性,此时 most field 可能比较合适;部分场景可以结合 best/most field 模型,比如电商搜索等
best_field 一般只计算最佳字段与搜索内容的相关性得分,ES 支持使用 tie_breaker 加入非最佳字段与搜索内容相关性得分的计算。下面公式假设 title 是最佳匹配字段,最终返回评分同时考虑了最佳字段和其他字段的相关性,只不过非最佳字段的重要程度被 tie_breaker 降权
\[score =S_{title }+ { tie\_breaker } \times(S_{overview}+S_{cast.name}+S_{directors.name}) \]
如果 tie_breaker 被置为 1.0,那么 best_field 就十分类似 most_field
白化象 & 认知偏差
白化象问题(albino elephant problem)是遇见这个问题的工程师对问题描述时举的例子,后来就用例子来表示这类问题。如下图所示,从直觉上看本应得高分的右侧文档却和左侧文档得到了一样的分数。这是以字段以中心查询方式固有的缺陷,以字段为中心的查询方式独立计算文档中不同字段的得分,没有从整个文档的角度计算相关性

认知偏差被很多中文书籍直译为信号冲突(signal discordance)。认知偏差是搜索引擎技术实现和用户对搜索引擎功能认识之间的差别。以论文搜索为例,搜索引擎内部常将论文的标题、简介、正文等不同部分作为不同的字段分别进行处理,然而在部分用户的搜索意识里,论文的标题、简介和正文应该一同处理。因为认知偏差的存在,很多时候搜索引擎会返回一些让人感觉莫名其妙的搜索结果
Disjunction Max Query
disjunction max query 也被称为 dis_max 查询,可以部分解决白化象问题。其中 dis 表示分离(或者离散),max 表示最大,从字面上来讲 dis_max 查询是分别使用子查询语句查询文档,返回分值最高的子查询分数作为最终分数。示例可以参考这里
下面查询语句会使用两条查询分别查找文档,使用最大子查询值作为最终文档评分。如果将 dis_max 修改为 bool,那么文档的分数将整合两条语句的分数作为最终文档评分
GET /_search
{
"query": {
"dis_max": {
"queries": [
{ "term": { "title": "Quick pets" } },
{ "term": { "body": "Quick pets" } }
],
"tie_breaker": 0.7
}}}
如果多个字段的查询语句相同,使用 multi_match 并设置 type 为 best_field 可实现 dis_max 查询并简化查询语句
以词为中心的搜索
以词为中心的搜索方式可以部分解决认知偏差和白化象问题。以词为中心的搜索场景下,每个词在计算相关性得分时会考虑所有字段
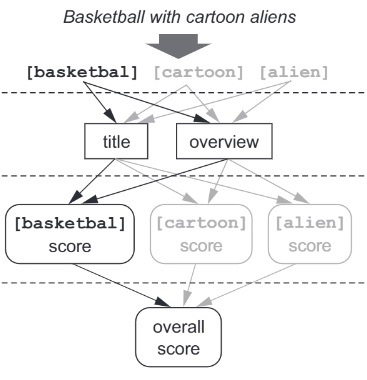
字段同步
字段同步是以词为中心的查询方式相比于字段查询方式的一个缺陷
以词为中心的查询方法会使用一个 token 查询多个字段,不同字段可能有不同的分析器,查询不同字段具体应该以哪个字段的分析器为准?可以考虑不同字段遍历一边所有分析器,这样时间复杂度就是 \(O(m*n)\),其中 m 表示字段的个数,n 表示所有字段存在的分析器种类个数。\(O(n^2)\) 时间复杂度的算法会极大的影响系统性能,且不同字段使用不同的分析器也会让文档的评分变得复杂,所以 ES 使用了最简单的方式,所有查询使用默认的分析器,这个现象称为字段同步
自定义聚合字段
自定义聚合字段就是将多个字段合并成一个字段,在 ES 或者 Solr 中自定义聚合字段也被称为拷贝字段(Copy field)。拷贝字段虽然造成数据的冗余,但解决了白化象问题
ES 中有关自定义聚合字段的功能可以参考官网 copy_to 。ES 6 之前 ES 默认为每一条记录添加了一个组合字段 _all,系统自动将其他字段合并到这个字段中,ES 6 之后 _all 被弃用
合理的对相似字段进行聚合可以减少一些问题,且可以简化搜索。《相关性搜索》第六章给出了一个例子,将电影中导演的名字和演员的名称进行了分组与聚合,部分解决了以字段为中心的白化象问题
cross fields
cross fields 方法也有字段同步的问题,如果不同字段之间没有通用的解析器,查询可能会报错。以词为中心的搜索在 ES 的 multi_match 中通过设置 type 为 corss_field 即可实现。
组合查询(严格&宽松)
利用 ES 提供的聚合查询接口对同一个查询语句使用不同的查询方式,最终综合查询结果来解决相关问题
以下面查询语句为例,第二个 multi_match 用于提升查全率,而第一个 multi_match 用于提升查准率。第二条查询语句使用了非常宽松贪婪的查询条件,只要有对应单词的文档就会被返回;第一条查询语句相对比较严格,使用了二元 token,匹配的文档会获得更高的分数
{"query": {
"bool": {
"should": [{
"multi_match": {
"query": "usersSearch",
"fields": ["directors.name.bigramed", "cast.name.bigramed"],
"type": "cross_fields"}
},{
"multi_match": {
"query": "usersSearch",
"fields": ["overview", "title", "directors.name", "cast.name"],
"type": "cross_fields"
}}]}}}
组合查询也有自身的缺陷,一旦宽松查询有着比严格查询更显著的信号,那么查询结果不会尽如人意。可以使用 boost 减少宽松语句的打分权重,细节可以参考这篇文章
查询解析器
Lucene 提供了支持 bool 查询语法的查询解析器,例如:
(name:Best description:Best) + (name:Laptop description:Laptop)
ES 中使用 query_string 支持 Lucene 的查询解析器,合理的使用 Lucene 查询语句可以实现以词为中心的查询。ES 版本迭代较快,query_string 在不同版本的功能区别可能较大,比如 ES 6 以后就直接移除了 use_dis_max 属性,所以 ES6 之前可以使用查询解析器实现 dismax 查询,ES6 之后就不行了
评分调整
查询的排名的优先级在不同的场景下不同,以电影搜索为例:精确匹配 > 部分精确 + 热度 > 某些特殊字段的匹配 > 其他字段的匹配
新闻搜索应给出时事要闻、餐厅搜索一般把距离较近的餐馆放在前面,不同场景对搜索结果有不同的要求,所以搜索也需要一定的定制化,需要对相关性搜索的评分做一些调整
一个简单的评分调整方式是使用上面介绍的组合查询:基准(宽松)查询 + 放大(严格)查询。使用宽松和严格的组合查询方式有个问题,严格查询语句的 boost 值应该设置为多少?这其实是个无法回答的问题,所以尽量还是不要使用这类方式
boost & boost 分层
boost 是最基础的评分调整手段,即为不同的字段赋予不同的权值,ES 中 bool 查询是支持 boost 的,其他支持 boost 的查询可以参考 ES 官网
为不同重要程度的信号赋予有明确层级的 boost 分值,可以很方便区分信号之间的重要程度。比如将最重要的信号 boost 设置为 1000;次要的设置为 100;其他的设置为 10 或者更低
function score
使用 function_score 提升符合一定要求记录的评分,ES 对 function_score 的支持可以参考官网。使用 function score 方法可以为满足要求的记录评分乘以一个 boost 数值,从而提升或者降低相关度。搜索时事新闻时可以使用 function score 根据新闻日期修改文档得分
function score 提供了现成的工具可以实现按照指定字段属性的权值衰减,比如按照记录的时间以指数的形式衰减其搜索评分。细节可参考《相关性搜索》第 7.4.7 小节
filter
使用 filter 可以直接过滤掉满足要求的记录
精确匹配
用户查询语句精确匹配字段时可以考虑将相关记录放在返回结果前(给一个相当大 的 boost 值)。以用户查询演员名称而言,精确匹配之后可以按照电影上映时间逆序返回相关电影。为实现精确匹配,我们需要使用一些工具
基于 SENTINEL
在某些 token 的前后插入标记,插入过程可以使用自定义 ES 插件,搜索时使用短语搜索工具,比如 phrase。插入标记的字段在查询时也需要携带标记,比如:SENTINEL_BEG query-string SENTINEL_END
基于 function score
使用自定义的评分过程增加精确匹配的分值
constant score
精确匹配时可以忽略 TFIDF 值,此时可以使用 constant score 查询
使用已有评分信息
已经上映的电影有用户的打分,可以考虑直接使用这个分数来修改记录的查询得分,此时可以利用 ES 中的 field_value_factor 。其他可用的评分信息还有票房收入、人气指数和页面访问量等等
相关性反馈
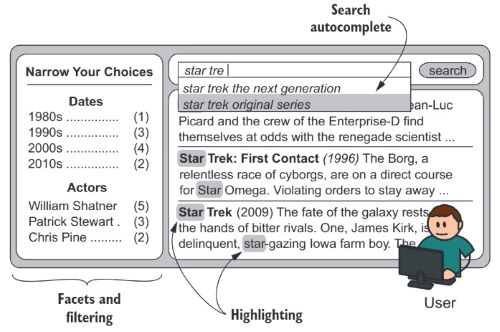
相关性反馈通过与搜索用户的交互来改善用户的搜索结果和搜索体验,可用方式如下:
- 向用户解释查询与匹配过程,帮助用户更好的理解搜索结果。例如可以使用 ES 提供的 highlight 实现关系信息的高亮
- 纠正用户的输入错误,在用户搜索的同时提供一些服务
- 实时搜索(使用
match_phrase_prefix在输入的同时展示搜索结果);搜索补全与搜索建议(可以利用 ES 提供的 Suggests 工具)
- 实时搜索(使用
- 向用户推荐多样化结果,比如其他类型的相关搜索
- 向用户展示搜索结果的分布情况,便于用户过滤搜索结果
- 其他
语义和个性化搜索
个性化搜索会结合用户的个性与特点返回符合用户口味的搜索结果,个性化搜索已经开始有了推荐的意味;语义搜索通过分析用户的意图,而不是简单的使用搜索词
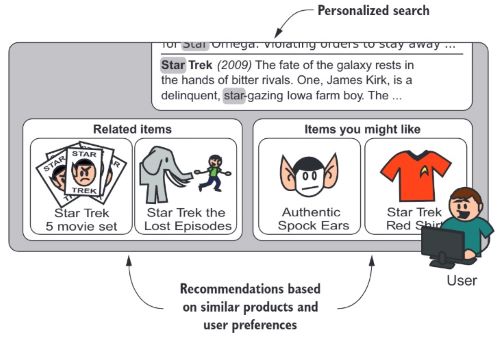
个性化搜索需要结合用户的历史行为,这个分析过程和大数据息息相关,本文不做深入介绍。以用户年龄为例,同龄人有一定的相似性,某个年龄段用户搜索时可以将同年龄段其他用户喜欢的产品放在前面。结合协同过滤等推荐算法可以进一步改进搜索结果
给物料文档建立索引时可以将其受众信息一同加入到索引中,用户查询时系统自动添加用户信息到查询语句中,如此便可以实现产品与用户之间的关联
构建语义的方法
同义词 / 机器学习
推荐是广义的搜索
略
其他内容
使用 ES 进行实验
为了简化操作我们可以使用 ES7 的机器学习模块导入数据或者直接使用 Dev Tools 上传,请参考这里,但实验数据比较大时 Dev Tools 上传不方便。《相关性搜索》所使用的 代码仓库 内容相对比较老,可以下载并使用 anaconda2 的控制台窗口进行实验。书籍仓库中的代码需要做一些修改才能在新版本 ES7 中执行,比如发起 HTTP 请求时如果 http body 中有数据,需要显式说明 body 数据类型:
resp = requests.post("http://localhost:9200/_bulk",
data=bulkMovies,
headers={"Content-Type":"application/json"}) # 需要手动添加
print resp # 查看返回结果
Kibana 返回的数据类型是 JSON 格式,为方便查看,可以使用这个网站将 hits 数组转换为 CSV
可以直接下载 tmdb_es_ml_importable.json (PWD:jiahu123),使用 Kibana 首页的导入功能(Upload a file)导入数据
Lucene 简介
Lucene 是 ES/Solr 底层的存储与检索工具,类似于 InnoDB 和 MySQL 的关系。Lucene 除了提供查询接口,也提供了配置与分析接口,比如运行时索引合并与修改、历史查询日志等。Lucene 4 的组合和结构图可以参考 Apache Lucene 4
概念
- IR,information retrieval
- Search Query(搜索分析),将用户输入的单词或者短语转化为 Lucene 可识别的语法
- boosting,Lucene 中的 boosting 可以用在索引和查询文档时,通过给不同的**域设置不同的分数(加权)**以提升或降低其在查询中的相关性。boosting 可以应用在文档和字段上,以提升某些文档和字段的相关性
- 其他
Lucene 的特点
- Lucene 可不保存原始数据。插入 lucene 索引文档并建立索引的字段,其值域数据并不一定需要写入索引中。单独存放的值域数据在查询时也会被匹配,但默认情况下返回值是不包含这类值域数据的
- Lucene 中的数据没有统一的模式。加入同一个索引的文档可以有不同的字段
- Lucene 支持增量索引。部分搜索库添加新文档后需要重新索引所有文档,lucene 利用段和段的周期性合并实现增量索引
- 灵活的配置。相同文档的不同字段可以有不同的属性,比如不同的分词器、是否保存、是否索引等选项
文件检索过程
- 提取,从数据源提取为文档,比如从数据库中、从 Web 等。只有数据转化为文档才能被搜索引擎索引,ES 使用 JSON 格式的文档
- 充实,将有助于相关性检索的信息加入到文档中,例如添加额外的描述
- 清理,例如纠正拼写错误、去重、去除 Markup 标记(HTML、XML 标签)等
- 强化(提取词干、添加同义词、近音词、类别属性等),分类/聚类、情感分析等。一些场景下的索引会提取文档中特定的内容到指定的字段,比如日期、地址、标题、摘要等等
- 合并,填充缺失的一些信息等
- 分析,将文档转化为可匹配的 token
- 任何数据类型都可以被分词从而生成 token,例如图片、音频、视频等
- 搜索引擎在匹配 token 的时候需要逐字节对应,所以分析过程非常重要
- 字符过滤。以 HTML 页面为例,字符过滤将去除页面中无用的 tag ;有些语言的重音去重操作
- 分词处理。引入同义词,去除词根等等
- token 过滤。所有单词小写,去除 stop words
- 索引,生成倒排索引
Lucene 3 索引文件格式
Lucene 底层使用多个索引段(Segment)管理属于同一个索引的索引数据,每个段文件格式与功能相同,只是存储着不同的文档的索引信息,下图展示了同一个索引下的两个索引段 0/1,统一个索引段中的文件有着相同的文件前缀。查询时 Lucene 会访问所有段目录,综合不同段的结果后返回最终结果

索引段默认使用多个不同文件分别保存不同类型的数据,例如项向量(.tvf)、域数据(.fdx & .fdt)、归一化信息(.nrm)、项频率(.frq)和项位置(.prx)等,细节可以参考 Lucene 3 官网文档

段文件(Segments File,.gen & _N 文件)是 Lucene 管理索引段的工具,查询时 Lucene 会先打开段文件查看哪些段和段文件是有效的,然后对有效的段进行查询。存在的段目录并不一定都是有效的,Lucene 在做段合并(merge)时未完成合并的临时段目录是无效的。存储到磁盘上的索引文件是不允许修改的,所以 Lucene 只会在合并时完成修改并在合并完成后删除旧的段目录
按照 Lucene 的设计,检索与删除可以同时进行,检索在删除动作将所有内容提交到磁盘前使用的依旧是老数据。未刷新的 IndexReader 对象可能无法感知文件的删除动作,所以尽量不要使用持久性质的 IndexReader 对象(随着Lucene 的发展,IndexReader 可能会自动刷新可用段)
Lucene 索引可以使用 luke 可视化,正排和倒排索引的细节本文不做介绍,可以参考其他资料,例如 Lucene 倒排索引简述 / 《Practical Apache Lucene 8》,注意不同版本的 Lucene 索引文件有一定的区别。为了提高数据的查询速度,Lucene 使用了一些不常见的数据结构和算法,比如 Burst-trie 等
新文档与索引段
每次新增文档时 Lucene 都会创建一个新段来保存新增文档的索引信息,Lucene 通过频繁创建/合并索引段实现增量索引功能
频繁创建/合并段需要打开大量文件描述符,但大部分系统对单一进程可打开的文件描述符个数有限制。Lucene 可以通过频繁合并小的索引段减少索引段的个数,但这会增加系统负担。为减少频繁创建/合并索引段造成的系统负担,Lucene 支持复合索引段,即将分立索引段中的多个文件打包成一个文件(.cfs),这样创建/合并索引时每个线程只需使用三个文件描述符。Lucene 支持在运行时切换分立索引段和符合索引段
删除文档
为提升系统性能,对文档执行但删除操作并不会实时触发磁盘操作,Lucene 会先标记文档已被删除,后续索引合并时才会回收对应磁盘空间。Lucene 的标记删除特性非常适合系统的横向扩展,增加计算机器就可以提升整个系统的查询吞吐量,而存储机器在磁盘 IO 没有占满的前提下可以不用扩展
标记/合并 删除
Lucene 使用了和 InnoDB/Redis 类似的删除策略,删除数据时数据会被打上删除标签,此时其依旧占用磁盘空间。被删除数据所占用的磁盘空间只有在段合并时才会被释放。Lucene 3 的索引段使用 .del 文件保存标记删除信息
部分接口
查询
Lucene 提供了很多种类的查询接口,比如:
- TermQuery,通过 term(项)进行查询
- TermRangeQuery/NumericRangeQuery/PrefixQuery
- BooleanQuery,组合查询。Lucene 3 组合查询示例如下
- PhraseQuery,短语查询,查询的短语其组成单词不一定相邻,PhraseQuery 可以设置短语间单词距离的规则
- WildcardQuery,通配符查询;FuzzyQuery,编辑距离查询
- QueryParser,表达式查询:
+pubdate:[20100101 TO 20101231] Java AND (Lucene OR Apache)。QueryParser 会将查询语句转换为上面介绍的查询对象然后进行查询,有相关工具可以查询转换过程于细节。Lucene 3.1 时当前对象提供的查询语法不能覆盖所有 Lucene 提供的查询功能 - 其他
优化/评分细节
Lucene 提供了 optimize 接口可以用于索引优化,比如指定索引段段个数。索引合并的过程会占用大量的 CPU 和 IO 资源,合并期间需要不小于已有数据 3 倍大小的磁盘空间。索引合并可以提升检索速度但不会提升索引速度
Lucene 提供 explain 接口用于显示文档的评分细节