Elastic Stack 7 简介
参考资料:《Elasticsearch 7 Quick Start Guide》 & code // 《Advanced Elasticsearch 7.0》 & code // 《相关性搜索》 & code // 官方 7.15 文档 //
Elastic Stack 迭代频繁,大版本之间有不少区别,查询资料时要按照当前使用的版本进行查询
腾讯云或者阿里云提供一个月免费的 Elastic Search 试用。EStack 很多工具都可以跨平台使用且安装方便,具体可以参考官方文档进行安装
Elastic Stack 可以用于解决不同的业务问题,例如:
- Product search / Web searches and website searches (with Apache Nutch)
- Log and security analytics,比如使用 Beats、Logstash 和 Kibana 等实现日志拉取、存储、查询与分析
- Metrics analytics
- APM(Application Performance Monitoring),使用 APM 可以实现应用程序性能监控
- SPM(System Performance Monitoring),利用 Beats 工具(例如 Metricbeat、HeartBeat 等)上报服务器运行时参数可以实现系统性能监控与分析
- Machine learning,EStack 的机器学习模块收费,但有 30 天的试用,细节请参考官网。结合 scikit-learn、Spark 等工具可以实现免费的 ES 机器学习与实时分析功能
- 如果对数据安全性要求不高,EStack 可以作为数据库使用;使用 EStack 作为搜索引擎从而实现第三方数据(MySQL、FTP、SMB 等等)的检索
Elastic Stack
Elastic Stack 7 的组成与功能大致如下图所示:

- Kibana 是可视化工具,方便用户与 Elasticsearch 交互
- Elasticsearch 是 EStack 的核心,用于数据的存储、检索与分析
- Logstash&Beats 提供一些工具方便用户将数据导入 Elasticsearch,新版本的 EStack7 可以很方便的使用机器学习模块导入小于 100MB 的数据(CSV、JSON)
- ES-Hadoop 可以实现 ES 分析 Hadoop 数据并使用 Kibana 可视化分析结果
- APM Server 用于监控系统与应用程序的性能
Elastic Search
graph TB
A[ES]
B[concepts]
C[index]
D[mapping]
E[multi field]
F[Doc]
G[Ingest]
H[Analyzer]
J[Search]
K[URI]
L[DSL]
M[scroll<br/>search_after]
N[bool / boosting<br/>function_score]
O[aggs]
P[ES SQL]
R[join]
A-->B
B-->C
B-->D
D-->E
B-->F
B-->G
D-->H
A-->J
J-->K
J-->L
L-->M
L-->N
L-->O
L-->P
F-->R
Elastic Search(ES)是 EStack 的核心,包含存储、检索与分析功能,可以通过阅读ES 简介快速了解 ES 的功能。ElasticSearch 可以以 service 的形式安装到 windows 实现开机自动启动。ES 服务默认端口 9200
概念
ES 基础
- 索引(index) ,类似于 MySQL 中的表,ES 官方给出了 SQL 概念和 ES 概念的对照表
- ES 可以灵活配置索引参数(比如分片个数、缓存大小等等),其中一些参数需要在创建真实索引前配置;有些配置可以在索引创建之后配置,比如可以使用
_split将大索引分为多个小分片提高检索速度;索引中可以定义自己的 analyzer - index template,index 模板可以提升创建索引的效率
- aliases,ES 可以给多个 stream/index 设置一个别名(分散数据可以提高搜索速度),这样就可以使用别名代表一组 index;创建别名的过程可以重新索引(index)数据,并减少空间占用
- Rollover index,滚动索引。当索引文件满足一定要求时(比如大小、记录时间等),ES 可以自动创建新的索引文件,并将新数据写入新索引中。这个特性非常适合日志分析
- _reindex,使用 reindex 方法可以从已有的索引创建新的一个或多个索引,创建新索引的同时可以执行一些过滤策略与其他动作。已经写入数据的索引不能修改 mapping 参数,为实现 mapping 修改,可以创建一个新的索引然后执行 reindex 方法
- 可以使用 cat 命令查询 ES 中存在的索引,例如:
GET /_cat/indices
- ES 可以灵活配置索引参数(比如分片个数、缓存大小等等),其中一些参数需要在创建真实索引前配置;有些配置可以在索引创建之后配置,比如可以使用
- mapping,如果把 index 看作 MySQL 中的表,那么 mapping 就相当于 SQL 表的列定义(模式)
- mapping 信息可以通过
GET {index}/_mapping的形式进行查询。使用 mapping 可以优化搜索 - dynamic mapping,使用 ES 时可以不定义 mapping,此时 ES 将自行判断字段类型并做相应的处理,ES 使用 Dynamic templates 定义默认的 dynamic field mapping,用户可以修改这个模板实现自己的映射规则。可以通过
Get {index}/_mapping命令查看索引的dynamic_templates - static mapping,与 dynamic mapping 对应,static mapping 场景下用户明确定义字段的类型和属性。使用 static mapping 时没有显式设置的字段将不会被保存与索引
- Field data type,mapping 可以指定每个字段的数据类型,不同类型的字段可以使用不同的分析工具。相同的数据类型可以有不同的格式,比如 date 的格式是可以指定的。数据类型可以分为三类
- 简单数据类型,比如 text、bool、date 等
- 复合数据类型,由简单数据类型嵌套而形成的数据
- 特殊数据类型,比如
geo_shape、geo_point等
- Multi-field mapping,ES 支持为相同的字段赋予不同的数据类型,如此同一个字段就可以使用不同的分析工具。使用 multifield mapping 可以实现更丰富的相关性搜索
- runtime field,执行 query 语句时可以给设置运行时 mapping 参数 ,这样可以在查询时指定字段类型。在查询语句中指定临时 mapping 的方式请参考:define runtime field
- mapping params,mapping 除了可以设置字段的类型也可使用 mapping params 设置字段的分析、存储等属性。比如可以使用 “enabled”:false 禁止为某个字段创建索引信息;
analyzers可以用来设定字段的分析器(即预处理器、分词器、过滤器)
- mapping 信息可以通过
- Documents,一个 Doc 可类比于 MySQL 表中的一条记录。ES 将实际文档存储于 JSON 格式中,单个 JSON 文档常使用命令
PUT /{index}/_doc/{_id}添加进索引,_id是可选项;使用命令GET /{index}/_doc/_id可以查询指定 id 的文档- 类 pipeline 操作(
_mget、_buck、_update_by_query等)。为减少网络耗时,ES 支持一次操作多个文档,也支持一次执行多个动作
- 类 pipeline 操作(
- metadata field,元信息。比如 ES 的查询结果中
_source对应着 doc 原始的 JSON 内容;_size表示_source的大小 - clusters/nodes/shards/replica
- 每个 index 可以有一个或多个 shards(分片);每个 shard 是一个完整的 Lucene 倒排文档;每个 shard 可有零或多个备份,即 replica;ES 一般不允许数据和备份数据在同一个节点(node)中;多个 node 组成一个 cluster(集群)
- 分布式索引一般有两种方案,一种是按文档划分,一种是按单词划分。前者每次查询会涉及所有节点,后者每次只涉及部分节点,但后者扩展性与查询方式都比第一种要差,所以第一种方式比较常见
- 安全管理,ES 有不同级别的安全设置,minimal auth 可以设置账号和密码,使用此功能需要 Java11 或以上
- Data shipping,将数据从一个位置传输到另一个位置。下文介绍的 Beats 是 EStack 中常用的 Data shipper
- Data ingestion,包括数据的采集、清理和转发。下面介绍的 Logstash 是 EStack 常用的 Data ingestion 工具
文档的索引与检索过程
细节请参考《Advanced Elasticsearch 7.0》第三章

Ingest APIs
插入到 ES 的原始文档一般都需要进行一定的预处理,比如大小写和符号的转换等等,这些功能可以用专门的服务来完成(比如 logstash),也可以使用 ES 提供的 Ingest APIs 功能实现
Ingest Pipeline 可以看作多个函数的组合,数据插入到 ES 时会先触发定义好的 Pipeline,数据被 Pipeline 中的函数处理完成之后才会进行后续行为。ES 中定义的 Ingest Pipeline 可以用在不同的 index 中,而且不用引入其他服务,使用与管理都比较方便,介绍与简单的使用可以参考这篇博文
Analyzer
文档经过 ES Analyzer 分析后才能进行查询,Analyzer 过程如下。分析过程非常重要的,且和应用场景息息相关
- CharFilter 用于整理原始数据,比如去除 HTML 文件中的标签 tag,如
<div>/<head>等;mapping CharFilter 支持手动配置字符串替换规则,比如将you'll修改为you will;pattern_replace支持正则匹配与替换。一个 analyzer 可以有多个 CharFilter - tokenizer,分词器,将文章分解为便于用户检索的语义 token。一个 analyzer 一般只能有一个 tokenizer,但一个字段可以有多个 Analyzer,所以我们可以定义不同的 Analyzer 实现同字段的不同分析
- Filter,处理上一步生成的 token。TokenFilter 有多种类型,各有不同功能,比如去除 stop word 的 Filter。一个 analyzer 可以有多个 Filter
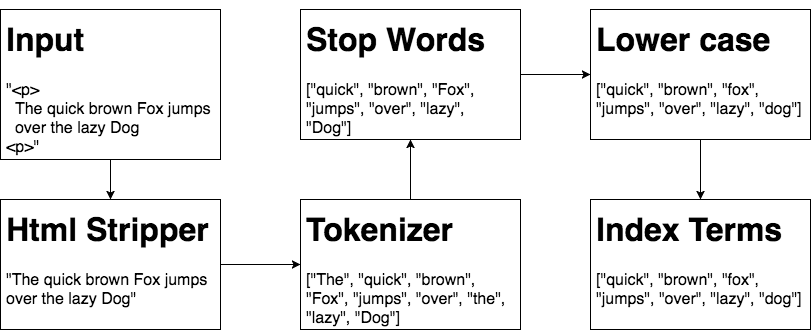
一个索引(index,可类比关系数据库 MySQL 中的一张表)根据其数据类型可能需要使用不同的工具,比如过滤、分词等,ES 提供了方便用户修改这些配置的接口
分析结果示例
ES 提供了一些内置分析器(analyzer),例如 standard、stop、simple、whitespace 等等,使用 ES 提供的分析接口可以直接获得 ES 对文档分析后的结果。使用下面命令可以查看不同分析器的能力(使用 Kibana Dev Tool)
POST _analyze
{
"analyzer": "standard",
"text": "Elasticsearch, is an awesome search engine!"
}
ES 支持手动设置分词工具、过滤器等工具。ES 内置了一些分词器,比如 standard、N-Gram 等
POST _analyze
{
"char_filter": ["html_strip"],
"tokenizer": "standard",
"filter": ["lowercase","stop"],
"text": "<p>Elasticsearch, is an awesome search engine!<p/>"
}
ES 还有其他很多不同类型的工具,这里不再一一列出
Search
ES 支持的查询语法十分丰富,下面做简要介绍
URI 接口使用示例
ES 支持直接使用 URI 的查询方式,即将参数放在 URL 尾部而不是 HTTP body 中,细节可参考官网 Search API
https://xxx.xxx/etf/_search?from=2&size=7&sort=symbol:asc&_source=false
以上面 URI 为例,from 表示查询偏移量;size 表示返回记录的个数;sort 指定排序规则;_source=false 表示不返回 _source 字段。上面 URI 没有给出查询的条件,所以 ES 会遍历排序后的数据并返回从第二条记录开始的 7 条。下面 URI 使用 q 属性引入查询条件
GET etf/_search?q=fund_name:ishares edge global&default_operator=AND&explain=true
上面 URI 使用了 explain 参数,ES 将返回文档的评分细节。这部分知识可以参考《相关性搜索》
下面的 URI 使用 keyword 分析器取代默认的 standard 分析器处理查询语句,keyword 会将整条查询语句当作完成的单元进行查询,而 standard 会对查询语句进行分词,所以下面语句的查询结果和上面语句的查询结果区别较大
GET etf/_search?q=fund_name:ishares edge global&default_operator=AND&analyzer=keyword
URI 查询还支持一些通用的属性,比如 pretty,具体细节请参考 common options ;URI 支持节点信息查询,例如 health/state 等,其他工具可以查询 Cluster API
Request Body Search
URI 查询支持的功能有限,且复杂的查询语句很难使用 URI 方式进行描述。ES 支持 REST 接口使用更复杂的方式查询数据,示例如下。注意 JSON 是没有注释语法的,下面的 # 在真实环境中不存在
GET idx/_search
{
"from" : 0, # 类似于 MySQL 的 offset,默认为 0
"size" : 100, # 类似于 MySQL 的 limit,默认为 10,可配置默认值
"query": {
"term": {
"uid" : "123456789"
}}}
URI 和 request body 查询方法有一定的对应关系,比如 from 和 size,其中 query 对应 URI 中的 q。ES 提供了很多不同种类与功能的 API,细节请参考官网 REST API介绍,下面给出几个比较典型的工具
分页首选 scroll/search_after
ES 支持使用 from 和 size 实现分页查询,这和 MySQL 的 offset 和 limit 类似。少量数据使用 from/size 比较方便,大量数据使用这类工具对于深分页而言比较消耗资源。from/size 的操作需要先在所有分片中查询符合要求的数据,然后根据 from/size 返回数据。如果只是需要查询数据的后一部分,那么大部分查询就被浪费了。大量数据的分页返回比较好的方法是查一次返回多次,每次返回不同的查询结果页。ES 提供了几种分页工具: scroll 和 search_after
第一次 scroll 查询 ES 会返回一个 scroll id,后续 scroll 查询需要使用这个 ID。ES 在 scroll 场景下会保存第一次查询结果一段时间供后续的分页返回,这个保存时长由用户指定,用户也可以直接删除对应的 scroll 数据
第一次触发 scroll 查询时,scroll 会保存查询结果中的所有数据且会保留一段时间,这不适合实时高并发查询场景,因为太耗内存。ES 提供了另一个工具 search_after ,如果下一次查询知道上一次查询的一些结果,那么下一次查询系统就可以快速过滤一些不符合要求的记录(使用 search after 需要结合 sort,search after 使用已序字段来过滤数据),少用点内存。search after 是无状态的,所以相同的查询语句可能返回不同的结果;search after 和 from 不能同时使用
scroll 查询使用空间换时间。search after 因为是无状态的,所以其查询耗时和 from/size 差不多,只是不需要那么多的内存资源
Query DSL
Request Body 中可以使用 ES Query DSL(Domain-specific language)实现复杂的查询。查询语句可以分为两个部分:查询(query)和过滤(filter)。查询是有匹配得分的;过滤直接使用文档的属性进行判断,只有 true/false 两个结果
全文检索
ES 中支持全文检索的方法有 match、query string 和 intervals 等,下面分别做简单介绍。全文检索的特点是查询语句和被查资料都会使用分析器进行预处理
match
match 方法先将查询字段进行分词处理然后在指定字段里查看对应的 token 是否存在,多个查询单词之间默认使用 or 进行逻辑计算给出匹配分数,查询示例如下:
GET cf_etf/_search
{
"query": {
"match": {
"fund_name": { # 指定查询字段名
"query": "ishares global", # 查询字符串
"operator": "and", # 使用 and 逻辑计算匹配分数
"fuzziness": 2 # 模糊查询,两个编辑距离认为匹配
}}}}
与 match 功能类似的方法还有 match_phrase 和 match_phrase_prefix ,前者用于查询短语,即将整个查询语句当做一个 token;后者匹配前缀
multi match
multi_match 支持一次在多个字段中搜索
query string
query string 查询方法支持使用 Lucene 查询语法进行查询。支持 query stirng 查询的方法主要有两个:query_string 和 simple_query_string 。两者使用的语法不同且前者比后者更严格。示例查询如下
GET /cf_etf_sample/_search
{
"sort": {"rating":"desc"},
"query": {
"query_string": {
"query": "rating:[1 TO 3}"
}}}
intervals
intervals 对多个匹配之间做了一些规则上的限制,比如查询结果中 a 需要在 b 后面
Term-level
Term-level 查询是将整个查询语句当作一个整体进行查询,此时查询和被查字段不会做分词预处理。Term-level 查询方法有 term、range、exists 等,常用于时间范围、价格、ID 等查询。具体细节可以参考官网资料
match 中介绍的 match_phrase 会对被查字段进行分词而 Term-level 不会
组合查询
上面介绍的几种查询方式一次只能查一个字段或多个字段,使用上面方法实现多个字段之间的组合逻辑查询相对比较困难。ES 中用户可以指定多个查询语句之间的逻辑关系从而实现复杂的组合查询(Compound queries)
支持组合查询的方法有:bool、boosting、function_score 等,细节请参考官网,下面给出一个实例:
GET /_search
{
"query": {
"bool": {
"must": [
{ "match": { "title": "Search" }},
{ "match": { "content": "Elasticsearch" }}
],
"filter": [
{ "term": { "status": "published" }},
{ "range": { "publish_date": { "gte": "2015-01-01" }}}
]
}}}
嵌入查询脚本
ES 支持在查询语句中(一般是 filter 中)添加自定义的查询脚本。ES 支持多种脚本语言,其中 painless 为默认
Join Datatype
ES 是分布式搜索引擎,在这类服务上执行类 SQL 的 Join 操作将相当消耗资源。ES 提供的 Join 操作只能在同一个 index 中。ES Join 提供了同一索引中文档之间的父子一对多关联关系,子文档可以持续插入而不影响父和其他子节点,细节请参考这里
Elastic SQL

Elastic SQL 是 ES 6.3 之后在 X-Pack 中引入的,Kibana 集成了这个功能。利用 Elastic SQL 我们可以像使用 MySQL 一样使用 ES,比如使用 SQL JDBC 和 ODBC 连接 ES。当然一些高级的 SQL 特性 ES 还不支持,细节请参考官网
使用 bin/elasticsearch-sql-cli 可以进入 ES SQL 环境,随后就可以使用 SQL 创建或操控索引,示例如下:
SHOW tables;
DESCRIBE xxx;
SELECT symbol FROM cf_etf WHERE symbol LIKE 'ACW%';
ES SQL 支持 REST 接口,所以我们可以在 Kibana Dev tools 中使用 SQL 进行查询,示例如下:
POST /_sql?format=csv
{
"query": """
SELECT * FROM ef_etf ORDER BY symbol ASC
""",
"fetch_size": 1,
"page_timeout": "120s"
}
上面 format 用于控制查询返回的显示方式,有 txt、json、csv 等,细节请参考官网
其他内容
- _msearch,一次执行多条独立的查询
- _explain,给出文档等评分过程,可以用于分析文档被查询到的原因
- _validate,验证查询语句是否有问题,在执行耗时操作前可以使用此方法进行验证,避免中途因语法等原因造成的失败
- _count,仅返回匹配文档等个数
- field capabilities,查看字段支持等属性与功能
- Profiler,debug 工具,用于分析查询语句的耗时,可以用于优化查询语句
- Suggesters,ES 内置的搜索建议模块
聚合运算
ES 除了提供基础的搜索功能,还提供了数据分析功能,如数据字段的聚合(aggregations)操作,比如 sum、max、avg 等等
Matrix aggregations
Matrix 聚合提供一次统计多个字段统计学属性(比如均值、方差、协方差等)功能,至今还在开发,只有部分功能可用,细节请参考 matrix stats aggs
Metrics aggregations
Metrics aggregations 提供了常用的变量统计工具(sum、avg 等),ES 7.0 后添加了 地理位置 GEO 相关计算工具
Bucket aggregations
从名称上看可以翻译成桶聚合,这类聚合给出一个数据分布的结果,类似于直方图(histogram)
Pipeline aggregations
多个聚合计算的组合
ES Real-Time Analytics
结合 ES 的实时分析与机器学习有多种方案,比如 scikit-learn + ES 、ESHadoop + ES 等,本文不展开叙述,细节请参考其他资料(比如:《Advanced Elasticsearch 7.0》)
其他组件
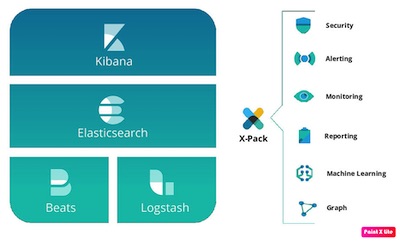
Kibana
Kibana 是 Elastic Stack 中的可视化工具。 Kibana 可以安装成 windows service 实现开机自启。默认端口 5601

Logstash
使用 Logstash 可以将不同来源的数据导入 ES。Logstash 是一个独立的服务,Logstash 通过读取配置(input config)主动读取数据源中的数据,处理后(filter)发送给第三方服务(output config),比如 ES
其他参考资料:https://www.xplg.com/what-is-logstash/
Beats
与 Logstash 相反,Beats 是客户端工具,Beats 将客户端的数据发送给第三方服务,比如 Logstash/ES。ES Beats 有很多种,比如 FileBeats、HeadBeats 等。FileBeats 会以 tail -f fille_name 的形式监控文件并转发数据
以 Metricbeat 为例,在系统中安装 Metricbeat 之后可以配置其采集系统状态(比如内存占用、CPU 使用率、Top 进程信息等)和一些服务的状态(比如 Nginx、MySQL、Redis 等)并发送给 ES。使用 Kibana 可以可视化查看这些数据(Kibana 中的 Observability/Metrics 页面可以查看数据)。使用 Kibana 的 ML 模块可以分析这些监控数据,进而实现监控告警等功能。EStack 中的 ML 收费
与 Metricbeat 类似,glance 是一个第三方系统信息提取工具,glance 默认置支持 ES,安装 glance 后执行相关命令(glances -C .\configs\glances.conf --export elasticsearch)即可将系统信息保存到 ES 中。如果想在 Kibana 中查看与分析 glance 数据,需要先创建 index pattern
X-Pack
X-Pack 是 Elastic Stack 的扩展工具,提供安全、监控、报警、上报、机器学习等功能,X-Pack 不像其他 ES 组成部分有独立的项目,X-Pack 的内容分散在各个组件中
随着 ES 的发展,很多 X-Pack 慢慢就成为了 ES 的默认组件,比如 ES 和 Kibana 监控。对于 ES 集群,可以关闭大部分节点的默认监控然后使用统一的监控平台,从而减少资源消耗并方便管理。ES 集群的监控功能依赖 Metricbeat,细节可以参考官网 cluster monitor
开启 ES 节点监控的方式请参考这里,监控开启后可以在 Stack Monitoring 中查看被监控组件的状态

Lucene
Lucene 是 ES 底层的存储与检索工具,类似于 InnoDB 和 MySQL 的关系
Enterprise Search
使用 Enterprise Search 可以很容易实现自定义搜索,且服务很容易部署,细节请参考官网 。ESearch 安装完成之后可以使用 URL 进行访问: http://localhost:3002 ,Kibana 中也可以访问 Esearch
Esearch 是 ES 7 之后引入的功能,暂时还不是很完善,如果想构造自己的搜索引擎,可以使用 yacy
ES 的配置示例如下
http.port: 9200
network.host: 0.0.0.0
xpack.security.enabled: true
discovery.type: single-node
xpack.security.authc.api_key.enabled: true
Kibana 的配置示例如下(配置完成后还需要执行一些操作添加密码,具体流程请参考官网):
server.port: 5601
server.host: "0.0.0.0"
server.name: "ELK"
elasticsearch.username: "kibana_system"
elasticsearch.hosts: ["http://192.168.8.100:9200"]
enterpriseSearch.host: 'http://localhost:3002'
server.publicBaseUrl: "elk.xxx.xxx"
使用如下命令可以以 docker 的形式安装 ESearch:
docker run -p 3002:3002 -e elasticsearch.host='http://192.168.8.100:9200'\
-e elasticsearch.username=elastic -e elasticsearch.password=euxxxxrhj \
-e allow_es_settings_modification=true \
-e secret_management.encryption_keys="[4a2cd3f81d39bf28738c10db0ca782095ffac07279561809eecc722e0c20eb09]" \
--restart=always docker.elastic.co/enterprise-search/enterprise-search:7.15.2
web crawler
ESearch 内置网络爬虫,具体配置方法请参考官网