Elasticsearch 与性能调优简介
参考:《Elasticsearch 实战》 & code && Second Edition & code // 《Elasticsearch 源码解析与优化实战》 // ES 7.15 官方文档 //
这应该是未来很长一段时间最后一篇 ES 相关文章了……
现实中的搜索
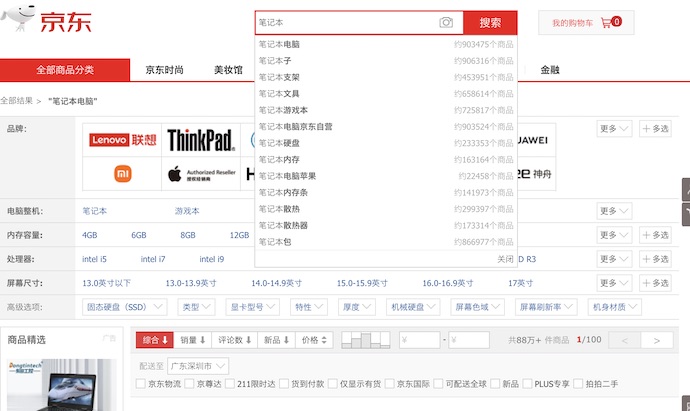
实用的搜索包含了很多功能,如下图左侧所示,用户可以根据搜索反馈进一步优化搜索。优秀的搜索引擎应该包含多种方便用户使用的功能,例如:下拉框提示、纠正、排序方式选择、种类限定等等
ES 基础
本文主要介绍 ES 相关概念与简单的优化方法,ES 常用命令可以参考这里。使用 REST 接口与 ES 交互时 URL 的模式如下所示:
<HTTP Verb> <index name>/endpoint/params
{ Request Body }
# 示例:
PUT movies/_doc/1
{
"title":"The Godfather"
}
概念
graph TB
A[cluster]
B[node]
C[主节点]
D[协调]
E[数据]
F[预处理]
G[index]
H[分片]
I[并行读写<br/>提升QPS]
J[近实时<br/>1s]
P[迁移<br/>2原则]
R[hash id<br/>%<br/>shards]
S[doc ID]
T[rnd<br/>post]
U[manual<br/>put]
V[modify<br/>reindex]
W[_version]
X[Green<br/>Yellow<br/>Red]
Y[事务日志]
A-->B
B-->C
C-->D
B-->E
B-->F
A-->G
G-->H
H-->I
G-->J
A-->X
G-->X
E-->P
H-->R
G-->S
S-->T
S-->U
G-->V
V-->W
A-->Y
索引
-
索引。ES 中的索引可以类比 MySQL 中的表,为减少存储与检索压力,一些场景下可以周期性的创建索引并为新索引赋予索引别名来减少单个索引的大小。ES 中存在类似于 linux 系统下隐藏文件的隐藏索引,ES 中的隐藏索引使用点作为文件名开始,隐藏索引常保存系统信息,kibana 也会创建一些隐藏索引
-
相关性,ES 支持为不同的字段设置不同的相关性计算方法,比如 BM25、bool 等
-
dynamic mapping 默认为 text 类型字段添加一个额外的类型 keyword 。keyword 类型更适合 term query 和聚合操作;intger 类型更适合 range 操作。额外的 keyword 字段解决了 text 字段不能排序的问题(
title.keyword) -
已经添加数据的索引可以添加新的字段但不允许修改 mapping 参数。可以使用 reindex 实现索引的修改
-
字段数据类型。ES 支持多种数据类型(每个字段可以赋予多种不同的数据类型),下面介绍一些特殊的
-
text,text 字段在存储 ES 前会先进行分析处理
token_count数据类型,token count 属于 text 类型,返回字段中 token 的个数
-
keyword,keyword 类型不会进行分析处理,keyword 字段的 value 就是完整的 token
- keyword 类别中还有
const_keyword和 wildcard 等类型
- keyword 类别中还有
-
advance type
- GeoPoint
- Object。从 JSON 格式上看,ES 中的 Object 数据类型是 JSON 中内嵌的 JSON 数据。Object 内部数组会被 flatten,相同字段的数据会被合并到一个内部字段中
- nested。nested 数据类型避免了 object 类型中 flatten 的问题,但降低了查询速度,应避免使用
- flattened。flattened 数据类型默认将所有写入到当前字段中的数据自动合并
- join。join 数据类型在同一个索引中引入了父子关系,join 会降低系统性能,应避免使用
search_as_you_type。当前类型会自动生成多种内部字段,具体细节请参考官网
-
-
索引文件时如果知道文档 ID 到生成方式,可以考虑使用 put 方法,如果不知,可以用 post 方法
-
Lucene 底层索引文件只读,所以文档的修改将触发整个文档的重新索引并创建新的文档,旧文档将标记删除
-
其他
索引操作
ES 对索引的配置可以分为三块:setting、mapping 和 alias。其中 setting 用于配置索引分片与副本、更新频率、压缩方法等内容;mapping 用于设置文档模式;alias 方便同时操作多个索引。使用 GET index_name 可以获得索引的详细信息,如下所示,每个索引等配置都包含上面三项
{
"books" : {
"aliases" : {...},
"mappings" : {"properties" : {...}},
"settings" : {
"index" : {
"routing" : { },
"number_of_shards" : "1",
"provided_name" : "books",
...
}}}}
索引 setting 配置分为动态(dynamic)和静态(static),已经开始使用的索引,其静态配置是不允许修改的,比如 number_of_shards,动态配置可以随时修改,比如 number_of_replicas
别名(aliase)
ES 支持为同一个索引设置多个别名,且别名可以用于不同场景,如:从不同的索引中查询或者聚合数据;reindex 时减少或者不停止服务
使用 ES 提供的 _aliases endpoint 可以一次执行多个别名相关的命令,比如下面的索引热切换
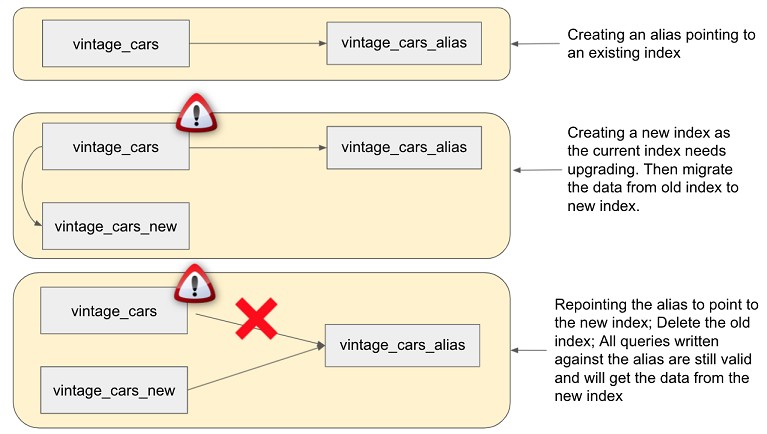
ES DSL 如下:
POST _aliases
{
"actions": [
{
"remove": {
"index": "vintage_cars",
"alias": "vintage_cars_alias" }},
{
"add": {
"index": "vintage_cars_new",
"alias": "vintage_cars_alias"
}}]}
索引模版

ES 7.8 之后对索引模板对设置做了一些修改,设置索引模板时需要确定 ES 的版本。如上图所示,ES 7.8 之后索引模板由两大部分组成:component(组件) & composable(成品)
分片
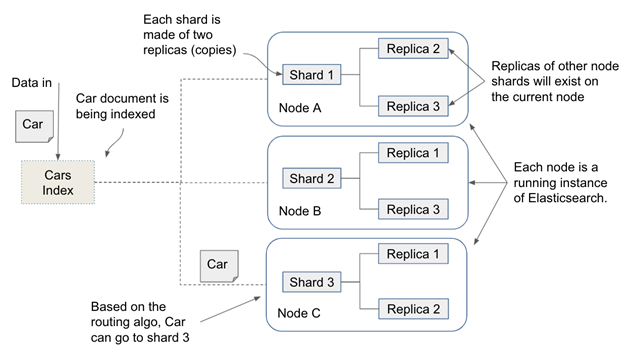
- 分片。ES 中的每一个分片对应一个 Lucene 索引。分片赋予索引并行读写的功能。因为 Lucene 的特性,每次合并拆分索引都将占用大量磁盘空间。分片可以配置副本,ES 查询语句会同等对待主副分片,所以增加副本个数可以提升系统 QPS 上限
- 文档与分片。ES 使用简单的方式为文档选择存储分片:
shard_num = hash(id) % num_of_shards,所以已经存储数据的索引不能修改分片个数 - 近实时搜索。写入到 ES 中的数据被索引之后才能查询,因为 Lucene 的特性,写入到索引段中的数据才能被检索而创建索引段比较消耗资源,所以 ES 会先缓存文档数据,周期性(1s)创建索引段并写入缓存的数据,故写入 ES 的数据默认 1s 后才可以查询
- 事务日志。ES 缓存一段时间数据后才会创建索引段,事务日志用于保存缓存数据信息,避免机器掉电丢失
- Type,ES8 之后 type 被移除。type 支持在同一个索引中存放不同类型的文档,因为不同类型文档的字段数量和类型不同且 mapping 参数只和 index 相关,所以 type 的存在使得数据的管理变得混乱
集群
- 同一个网络中使用相同 cluster.name (配置于 elasticsearch.yml 文件中)的 ES 节点属于同一个集群
- 使用相同的安装包指定不同的路径,同一台机器上可以启动另一个独立的节点:
./elasticsearch -Epath.data=../data2 -Epath.logs=../log2 - 节点类型。不同类型的节点应按照其职责配置不同的硬件
- 主节点(Master),主节点主要集群的管理,一般不存储索引数据
- 协调节点(Coordinators,默认类型,暂时无法通过配置去除节点的协调属性),如果查询频率比较高,单一主节点有可能成为瓶颈(数据的汇总与排序比较消耗资源)。集群中协调节点可以有多个,每个协调节点都保存了所有数据节点的信息。客户端在与主节点交互后,后续的查询访问协调节点即可
- 数据节点,保存索引信息,也是提供查询功能的基础节点。数据节点还可以细分为:
data_hot、data_cold、data_warm、data_frozen - 预处理节点,所有节点都可以成为预处理节点,但也可以设置部分节点为预处理节点。预处理节点主要用于数据 ingest 处理
- 其他节点请参考官网,例如:Transform node,当前节点与数据聚合操作息息相关;部落节点,部落节点支持联络多个集群;机器学习节点
- 集群&索引的健康状态:Green,所有主备分片(节点)正常;Yellow,主分片正常,部分备份分片不正常;Red,有主分片异常
- 集群扩容是分片数据迁移的两个原则,尽可能利用机器资源并提升数据的安全
- 数据需要均匀的分布在不同的机器上
- 相同编号的主备分片不能位于同一台机器上
- 客户端。因为查询比较耗时,所以 REST 和 API 客户端性能差距不大,ES 8 后不再提供 API 接口
- 其他
查询
ES 中的 Fetch 有两大类,GET 和 Search。前者使用文档的正排索引通过明确的参数(index+ID)获得文档,后者通过文档的倒排索引获取文档
Fetch 是读,所以可以从主或者副分片中获取数据,主副分片未同步时可能会出现文档不存在的情况
GET

- 协调节点计算路由信息获取文档分片位置
- 向主节点或者协调节点发送 GET 信息,因为 GET 请求有明确的参数,所以可以直接确定数据节点
- 返回数据
Search

- 查询请求到达主节点或者某个协调节点,节点按照负载均衡算法选择分片并将查询转发给包含索引分片的节点(部分或者所有)
- 数据节点执行查询语句。此时主副分片都有可能参加查询
- 主副节点返回数据,协调节点综合各分片返回数据后返回查询结果
性能优化
数据写入 ES 的流程如下所示
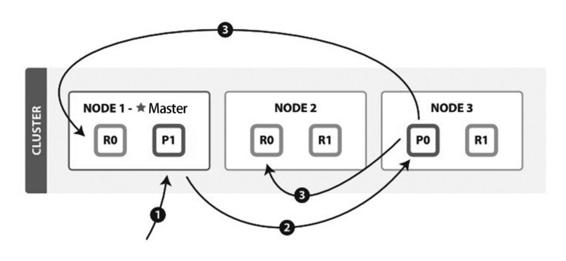
- 通过文档 ID 计算文档所处主分片
- 向文档将要保存的主分片节点发送写入信息
- 主分片写入完成后同步备份分片
ES 节点
graph TB
B[write]
C[index]
G[interval]
H[log flush]
I[new index]
J[bulk<br/>API]
K[avg<br/>disk]
L[more<br/>cache]
M[auto<br/>ID]
N[less]
O[keys]
P[anasys]
Q[index<br/>options]
R[no norms]
S[no pos...]
B-->G
G-->H
G-->I
B-->J
B-->K
B-->L
C-->M
C-->N
N-->O
N-->P
C-->Q
Q-->R
Q-->S
提升写入速度
ES 默认配置权衡了数据的安全性、查询和写入速度,一些场景下如果对安全性和查询没有那么高的要求而对写入速度有非常高的要求,可以考虑使用如下手段。官网也给出了一些方法
- 增加事务日志 flush 磁盘的间隔与缓存大小(调整
index.translog.*),ES 默认每条访问都 flush 事务日志到磁盘 - 增加索引刷新间隔(
index.refresh_interval)。ES 默认 1s 刷新一次索引,如果对实时查询没有要求,可以考虑增加这个间隔 - Lucene 段合并优化
- 调整索引缓存大小(indexing buffer),indexing buffer 是创建索引时使用的内存空间
- 使用 bulk 请求,但单次 bulk 请求数据量尽量不要超过数十 MB
- 让分片均匀分配在磁盘中。ES 默认使用磁盘阵列中剩余空间较大的磁盘,这种分片方式对磁盘均衡很不友好,可以考虑设置轮询磁盘的方式创建分片
提升索引速度
- 尽量让 ES 自动生成 ID
- 配置 mapping,减少字段数量(部分字段不写入 ES)、禁止某些字段的索引过程(enable:false)、减少字段长度、使用简单的分析器等等
- 配置 source 字段将索引与数据分离,这类配置适用于高 IO 低 CPU 的场景。
_source字段用于保存文档的原始数据,不需要存储的数据可以使用 exclude 进行过滤 - 禁用
_all,ES 6 之后 all 默认禁用,如果需要此类功能可以使用copy_to - 禁用评分(设置 norms 为 false)。日志场景下我们不需要相关性评分,可以关闭这个功能
- 调整
index_options,减少不必要的索引信息,比如 doc 数量、词频、positions、offsets 等 - 使用非精确查询;限定查询的分片个数,有些场景不一定需要查询所有分片
集群与硬件
graph TB
B[cluster]
C[others]
I[SLA/QPS]
J[nodes]
K[sharde]
L[less 50GB]
M[Replica]
N[scatter req]
O[num]
U[1GB JVM<br/>less 20 shards]
P[swap]
Q[less]
R[JOIN]
S[embed]
T[merge<br/>shrink]
B-->I
B-->O
O-->J
O-->K
O-->M
B-->L
B-->N
C-->Q
Q-->P
Q-->R
Q-->S
C-->T
L-->U
磁盘与内存空间优化
- 配置 mapping 的 index(倒排)、doc value(正排)、norms、store 等参数控制 ES 需要存储的数据
- 调整动态 mapping 方式,减少不必要的映射类型
- 禁用
_source;设置合适的压缩方式; - Java VM 最大最小内存要设置成一致,避免系统级别的内存回收;ES 单节点 VM 内存大小控制在 32GB 以内,Java VM 对 32GB 以上的堆空间利用率较低
集群配置
合理的设置 ES 集群可以最大化利用资源,下面对 ES 集群的使用提供了一些建议
- 确定数据量、QPS、SLA
- 集群节点数尽量控制在 100 以内,上千节点将给主节点造成较大的管理压力;集群总分片数控制在数十万内
- 单分片磁盘占用尽量不要超过 50GB(github 使用 128 个分片每个分片 120GB 来索引代码数据);每 GB JVM 内存管理不超过 20 个分片;机器配置尽量相同,避免短筒效应
- 避免将请求固定到指定的协调节点上,避免单节点压力过大
- 请求量很大时可以考虑多设置几个分片
其他提速方式
- 禁用 swap;禁用远程文件系统;
- 避免嵌套(nested)数据结构(比常规数据慢数倍)与 JOIN(比常规查询慢数十倍);避免使用脚本(一定要用,优先考虑 painless 和 expressions)
- 为字段选择合适的类型,keyword 的效率可能比 long/int 更高
- 优化时间查询,使用固定区间可以有效利用查询缓存
- 执行 force merge/shrink 合并只读索引,减少资源占用
- 预热 global ordinals,在 mapping 中指定可以使用 term 聚合的字段,方便 ES 提前创建 global ordinals
- 调整查询表达式,合适的查询表达式可以减少查询时间
- 其他,略
部分特性
Suggesters
ES 提供了多种类型的 suggest 和辅助工具,比如减少重复输入的多字段 global-suggest 。下面对 ES 提供的不同类型 suggest 做简要介绍